Introduction
In my previous post about Intention-Based Development, we explored how documenting intentions through User Stories and Architecture Decision Records could guide AI-assisted development. However, it doesn’t deliver a full solution and defaults to a lot of Chat-based Development.
This post explores a next step, one that leaves us with a way to measure if we are delivering on our intentions. It holds true to the Human-in-the-loop (HITL) principles and does not create a black box, rather formalises methods already used in software development as a reward function.
so, how do we quantify and measure the success or failure of work based on our intentions?
Enter Test-Driven Development (TDD) and Reinforcement Learning (RL).
While TDD isn’t new, viewing it through the lens of RL offers a fresh perspective on how we can measure and optimize our development process. By treating our test suite as a reward function, we create a concrete, measurable way to evaluate our progress and guide our development decisions.
First, the basics of classic Reinforcement Learning (RL)
RL is an approach for training a model (any sort) and is a growing field thanks to developments over the past 10 years. AlphaGo is possibly the biggest “original” and reinforcement learning from human feedback (RLHF), successfully used by OpenAI for ChatGPT and it’s competitors is possibly the most famous.
In classic RL:
- Agent = The learner and decision maker that interacts with the environment (in our case, this would be the developer or an AI assistant making code changes)
- Environment = The world in which the agent operates (for code, this is our development ecosystem with its codebase, test suite, and tooling)
- State (s) = The complete description of the world where nothing important is hidden
- Action (a) = Ways the agent can change the state
- Reward (r) = Immediate feedback about the action’s value
- Value function V(s) = Expected long-term reward from being in state s
A picture says a thousand words though, so here’s a view of classic RL - the subscript t is a reference to time. This is important as the loop repeats itself until an end state.

For clarity, let’s cover a real-world, non-Tech example:
Think of teaching a dog to fetch. The state is where the dog is and what it’s doing, actions are what the dog can do (run, grab, return), rewards are treats and praise, and the reward function is the dog’s understanding of which behaviors lead to more treats over time.
The ball is thrown and the dog then makes a decision of what action to take. This changes the dog’s state in the environment and the ball thrower (note, the ball thrower is part of the environment, not the agent) calculates a reward based on the dog’s (this is the agent) action. If the dog runs to the ball, the ball thrower gives positive reward, if it ignores the ball, then encouragement/negative feedback is given.
This repeats until the dog (agent) repeatedly returns the ball.

The Marriage of TDD and Reinforcement Learning
OK, let’s think of your code as a state machine. Note, not the development process but the code. At any given moment, your code exists in a particular state, characterized by its current behavior.
That’s a bit too formal, let’s use a dog-fetch analogy; the code is the ball, the developer with their AI-Assistant is the dog, and the ball thrower is the test suite.
To clarify, testing code provides immediate feedback about our actions, just like the dog receiving a treat for successfully retrieving the ball, the Developer and AI-Assistant can relax after passing all tests.
So, the tests don’t just tell us about the current state - they reward or penalize specific development actions.
In this framework:
- The state of the code represents the current state (s)
- Code changes are actions (a) that transform the state
- Test results provide immediate rewards (r) about the action’s value

This isn’t just theoretical - it’s a practical way to provide immediate feedback. When a test fails, it’s effectively saying “that action led to an undesirable state.” When all tests pass, the action is rewarded.
The reward function is a very important part of RL. It forms a significant part of the value function. This blog post doesn’t include the value function as that felt like introducing too much mathelatical notation, so it’ll likely be a blog post in its own right. Reach out if you would like to know what Gt and q*(s,a) means is sooner. :)
In focusing on the reward function and TDD, I assume you have an understanding of what is valuable in software engineering. Maybe you disagree on some of the details doc umented here (e.g. what sort of tests), which is great, hopefully you see the wider approach and below shows how the details can be changed to any given project.
Defining the reward function
Let’s start with the basics. This is technical and has mathematical notation, I’ll do my best to explain, reach out if you’ve questions or have a read of Sutton and Barto’s excellent and freely available book on the subject.
In its simplest form, our reward function looks at two key metrics, ratio of passing tests and code coverage:
Rt = w₁*(passing_tests/total_tests) +
w₂*(code_coverage)
This simple reward function tells us:
- How many of our tests are passing (correctness)
- How much of our code is being tested (coverage)
For example, if after making a change we have:
- 9 out of 10 tests passing (0.9)
- 80% code coverage (0.8)
- Equal weights (w₁ = w₂ = 0.5)
Our reward would be: R = 0.5(0.9) + 0.5(0.8) = 0.85
Of course, we can discuss the value of code coverage and ratios of tests that may or may not be still valid until the cows come home. The purpose of this reward function is to sit in an Intention-Based Development approach. That requires setting the constraints (ADR) and goals (Tests) beforehand and/or updating them as the process progresses.
Now let’s add a bit more to the reward function, with a light nod to the value function and the long term value of a code base; code quality is critical.
Code Quality - Beyond Immediate Rewards
Consider these two implementations that might achieve the same immediate reward:
# Implementation A - Simple
def calculate_total(items):
return sum(item.price for item in items)
# Implementation B - Complex
def calculate_total(items):
total = 0
for i in range(len(items)):
if items[i] is not None:
if hasattr(items[i], 'price'):
if isinstance(items[i].price, (int, float)):
total += items[i].price
else:
total += float(items[i].price)
else:
raise AttributeError("Item missing price")
return total
Both implementations could receive the same reward:
- All tests passing
- Full code coverage
- The same reward score (using the simple reward function above)
But Implementation B is clearly more complex and harder to maintain.
This highlights an important aspect of software development - the difference between immediate rewards and long-term value. While our tests provide immediate feedback, the true value of code includes factors that emerge over time.
This suggests our reward function needs to evolve to consider code quality metrics:
Rt = w₁*(passing_tests/total_tests) +
w₂*(code_coverage) -
(
w₃*cyclomatic_complexity +
w₄*cognitive_complexity +
w₅*dependency_count +
w₆*code_duplication_score
)
There isn’t one reward function, pick what’s right for you
It’s important to be clear there isn’t one reward function for all projects and code bases.
To highlight this let’s make a nod to other metrics that could help: Mutation Testing and an example of test weighting.
Other metrics: Mutation Testing
The tests become very important for the whole process, Mutation Testing is a process that can help keep the tests fresh and relevant. Adding a weighted score for this will mean that the Agent in the RL feedback loop can take appropriate action.
In plain terms, keeping tests fresh is known to be important. The motivation may be to help the developers maintain a manageable cognitive load, maintain the integrity of a CI/CD pipeline, or adapt to changes in requirements.
The tests are key, it may not be just Mutation Testing that you add, with an eye to the future, maybe the linchpin to increased automation.
Weighting metrics for features
Real-world example of test weighting: Consider a user authentication system. Your reward function might weight security-related tests more heavily than UI tests, reflecting the critical importance of security features.
There are numerous other evaluations that can be added to the reward function. It’s not all for free so a decision needs to be made, for your given business case, what level of reward is appropriate to invest in?
Now we’ve covered the reward function and the variety of metrics it can encapsulate, let’s look at making it a reality.
Practical Implementation
To confirm, this isn’t a full implementation, it’s the first step. The reality is that full details of metrics and tooling are complex and need their own deep dive in a future post. The purpose of this implementation is to so how the reward function directly translates to code. Those of you who have worked in a DevOps environment may see where external tools need to be called and the similarity to a CI/CD pipeline or pre-commit.
Setting up this approach requires thoughtful tooling choices. In this example Python is used, of course the approach can be implemented in any language. So let’s look at a basic Python implementation that captures our core concepts,.
Here’s a foundational implementation using Python:
class TDDRewardTracker:
"""
Implements the reward function:
Rt = w₁*(passing_tests/total_tests) +
w₂*(code_coverage) -
(w₃*cyclomatic_complexity +
w₄*cognitive_complexity +
w₅*dependency_count +
w₆*code_duplication_score)
"""
def __init__(self, weights: Optional[Weights] = None):
self.weights = weights or Weights()
def calculate_reward(self,
test_results: TestResults,
metrics: CodeMetrics) -> float:
"""Calculate the reward for the current state."""
# Positive components
test_component = self.weights.test_ratio * test_results.ratio
coverage_component = self.weights.coverage * (metrics.coverage_percentage / 100.0)
# Complexity penalty (normalized to 0-1 range)
complexity_penalty = self._calculate_complexity_penalty(metrics)
# Combine components
reward = (test_component +
coverage_component -
(self.weights.complexity * complexity_penalty))
return max(0.0, min(1.0, reward)) # Ensure reward is between 0 and 1
def _calculate_complexity_penalty(self, metrics: CodeMetrics) -> float:
"""
Calculate a normalized complexity penalty.
Returns a value between 0 (best) and 1 (worst).
"""
# Normalize each metric to 0-1 range using reasonable maximum values
cyclomatic_penalty = min(1.0, metrics.cyclomatic_complexity / 10.0)
cognitive_penalty = min(1.0, metrics.cognitive_complexity / 15.0)
dependency_penalty = min(1.0, metrics.dependency_count / 20.0)
duplication_penalty = metrics.code_duplication_score # Assumed to be already 0-1
# Equal weighting for each complexity metric
return (cyclomatic_penalty +
cognitive_penalty +
dependency_penalty +
duplication_penalty) / 4.0
A key aspect to this implementation is the developers preferences of development environment, and can be seen in the same light as the choice of an IDE. Just as developers have strong preferences about their development environment, they’ll have opinions about how reward function feedback is presented and acted upon.
The key is providing clear feedback and actionable choices - whether that’s suggesting specific refactoring steps or delegating decisions to an AI Assistant for a set number of iterations.
Again, this is the topic of a future blog post For now I’ll recap the benefits and challenges!
Benefits and Challenges
Benefits
- Quantifiable Progress
The reward function approach provides concrete metrics for measuring development progress, one that can be understood by a human and a machine.
- Automated Decision Support
With a well-defined reward function, automated tools can help guide development decisions.
This is a key area for me. Firstly the feedback could link to specific prompt templates that drive the actions, or the human is well versed in prompt engineering and crafts them on the fly.
- Balanced Development
By incorporating multiple metrics (test coverage, complexity, security, etc.), all responsibilities of an engineering team can be incorporated.
- Steady Progression
The reward function provides a step towards further automation. We saw operations and security shift left, I do not know which direction this sends responsibility but it does allow for a steady progression.
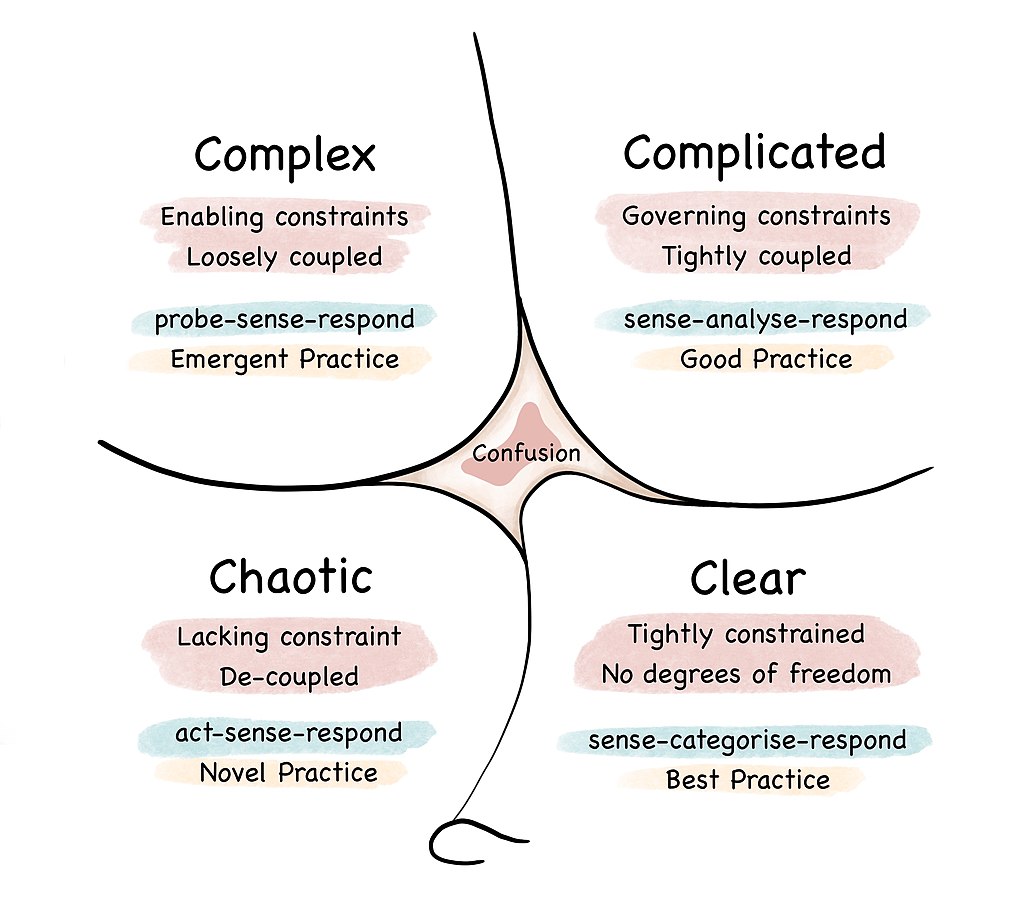
I am a fan of the Cynefin Framework, when you are in a complex environment, it is important to probe, sense what occurs, and respond in the best way you can. You build up constraints that enable delivery of value…
Challenges
- Tuning Weights
Determining appropriate weights for different components of the reward function requires experimentation and may vary by project type. This will largely be trial and error, though there isn’t a lot of complexity so there is good opportunity to probing for the best configuration.
- Optimistic / LLM Hype
So I’m probably being too optimistic, I say that as I only list one challenge! The reality is that it’s just a next step in the idea of Intention-Based Development. So the biggest challenge is making it work.
What’s next?
This process is a fun, path finding one. Largely rooted in a belief that code generation will be automated (“English in the next programming language”) and the important lessons I’ve learnt about what makes a valuable code base and system/product.
With that in mind the next steps are not yet fully clear, though following feels important:
- Specific details (i.e. code) of the reward function
- What is the agent - IDE, Code, something else?
- Linking immediate reward to long term value
In short, watch this space :)
Conclusion
This is an AI-Assisted conclusion… The point of the article is to document a technical bridge from intention, with documented constraints and requirements, to signals of successful or unsuccessful implementation.
This approach brings together several powerful ideas (ha, an LLM thinks they are powerful :-p):
- Immediate feedback through test results
- Quantifiable metrics for code quality
- A systematic way to balance different development priorities
- A foundation for AI-assisted development
Enough of that, let me share my key points on what this approach brings:
- refocuses the key development work from the “actual code” to the process of creating it
- it does this in a scientific way, so that it can progress consistently and in a credible fashion
With that last point, please share your thoughts:
- Email: [email protected]
- LinkedIn: https://www.linkedin.com/in/thompson-m